人工智能(AI)作為當今科技革命的核心驅動力,其理論與實踐的基石在于一系列經過時間檢驗的基礎算法。這些算法不僅構成了機器學習與深度學習的理論框架,更是人工智能基礎軟件開發中不可或缺的模塊。理解這些算法,對于開發高效、可靠且可擴展的AI軟件系統至關重要。
一、人工智能十大基礎算法概覽
以下算法在AI發展歷程中具有里程碑式的意義,廣泛應用于各類任務:
- 線性回歸(Linear Regression):用于建模連續變量之間的線性關系,是預測分析的起點。
- 邏輯回歸(Logistic Regression):解決二分類問題的經典算法,輸出概率值。
- 決策樹(Decision Tree):通過樹形結構進行決策,直觀易懂,是許多集成方法的基礎。
- 支持向量機(SVM):在高維空間中尋找最優分類超平面,擅長處理小樣本、非線性問題。
- 樸素貝葉斯(Naive Bayes):基于貝葉斯定理,假設特征間相互獨立,在文本分類中表現卓越。
- K最近鄰(K-Nearest Neighbors, KNN):一種簡單的基于實例的學習方法,核心思想是“物以類聚”。
- K-均值聚類(K-Means Clustering):經典的無監督學習算法,用于將數據劃分為K個簇。
- 隨機森林(Random Forest):通過構建多個決策樹并集成其結果的Bagging算法,有效降低過擬合。
- 梯度提升機(如XGBoost, LightGBM):通過迭代地訓練弱學習器(通常是決策樹)來糾正前序模型的錯誤,在結構化數據競賽中屢創佳績。
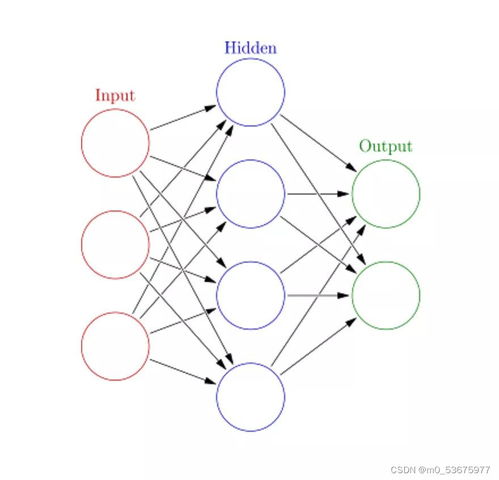
- 人工神經網絡與反向傳播(Artificial Neural Networks & Backpropagation):模擬人腦神經元連接,反向傳播算法是其高效訓練的核心,為深度學習爆發奠定了基礎。
二、基礎算法在AI軟件開發中的核心作用
在人工智能基礎軟件的開發中,上述算法并非孤立存在,而是作為核心組件被集成到更龐大的軟件棧和框架中。其作用主要體現在:
- 構建模塊化功能單元:基礎算法是軟件庫(如Scikit-learn、XGBoost)中的核心函數。開發者可以像搭積木一樣,調用線性回歸進行趨勢預測,使用K-Means進行客戶分群,或利用SVM進行圖像初部分類。
- 實現框架的核心邏輯:主流深度學習框架(如TensorFlow、PyTorch)的底層,高度優化了神經網絡的前向傳播和基于梯度下降的反向傳播算法。自動微分(AutoDiff)技術讓開發者能靈活定義和訓練復雜網絡。
- 提供特征工程與模型選擇的基準:在開發AI應用的Pipeline(流水線)時,邏輯回歸、隨機森林等算法常作為基線模型,用于評估特征的有效性和后續復雜模型的提升效果。
- 支撐集成學習與自動化機器學習(AutoML):隨機森林、梯度提升機等本身就是強大的集成模型。AutoML平臺在自動化搜索最優模型和超參數時,其搜索空間正是由這些基礎算法及其變體構成。
- 保障軟件的可解釋性與魯棒性:相對于復雜的深度模型,決策樹、線性回歸等算法具有更好的可解釋性。在開發對可解釋性要求高的軟件(如金融風控、醫療輔助診斷)時,這些算法往往是首選或重要組成部分。研究算法的魯棒性對開發安全可靠的AI系統至關重要。
三、開發實踐:從算法到軟件
在實際的基礎軟件開發中,流程通常包括:
- 需求分析與算法選型:根據具體問題(分類、回歸、聚類、降維)選擇合適的算法或算法組合。
- 數據處理與特征工程:這是算法有效性的前提,開發時需要集成數據清洗、轉換模塊。
- 模型實現與訓練:利用開源庫或自研代碼實現算法,并進行訓練與驗證。重點關注計算效率(算法復雜度)和內存管理。
- 評估與優化:集成交叉驗證、多種評估指標(準確率、F1分數、AUC等)模塊,并實現超參數調優接口。
- 部署與服務化:將訓練好的模型封裝成API、微服務或嵌入到大型應用中,涉及模型序列化、高性能推理引擎開發等。
- 監控與持續學習:開發監控系統跟蹤模型性能衰減,并設計管道支持模型的在線或離線更新。
###
人工智能十大基礎算法是連接數學理論與工程實踐的橋梁。在基礎軟件開發層面,深入理解這些算法的原理、優勢、局限及其實現細節,是構建高性能、可維護、可擴展AI系統的關鍵。未來的AI軟件創新,既離不開對這些經典算法的持續優化與新場景適配,也離不開在它們之上構建更高級的抽象和自動化工具。掌握基礎,方能駕馭未來。